
Stop Calling Prompt Chaining “AI Development”
The moment your “AI” can only act inside someone else’s UI, it is non-authoritative by design.

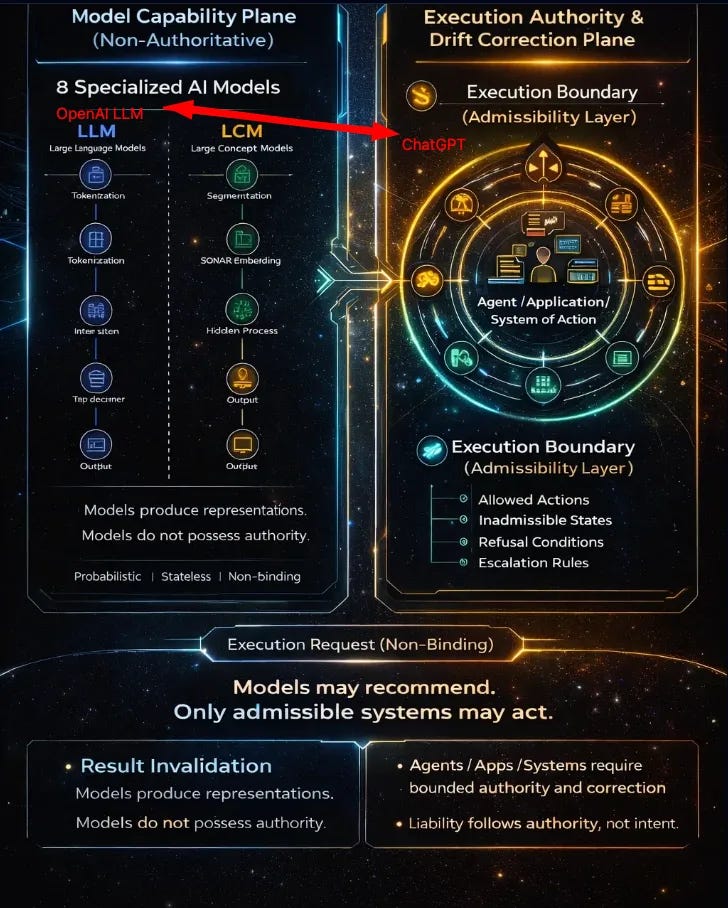
If all you’re doing is stringing together prompts inside ChatGPT (or Claude, or any hosted UI) and calling it AI development, you’re not building AI.
You’re using someone else’s product.
That’s not an insult. It’s a category correction.
Typing prompts into a hosted interface is no different than filling out forms in Salesforce and claiming you built a CRM. You didn’t. You operated a tool.
Real AI development begins where the UI ends.
The Confusion Everyone Is Having
The last two years collapsed three very different things into one word:
Models – probabilistic engines that generate representations
Interfaces – chat UIs, copilots, wrappers
Systems – software that is allowed to act
Most people are living entirely in #2 and claiming #3.
That’s why the discourse is so broken.
A prompt is not an application.
A workflow is not a system.
And a model is not an agent.
What Prompt Chaining Actually Is
Prompt chaining is interface scripting.
You are:
Passing text in
Getting text out
Maybe branching logic based on outputs
Maybe calling tools someone else exposed
You are not:
Defining authority
Enforcing constraints
Owning execution
Bearing liability
The moment your “AI” can only act inside someone else’s UI, it is non-authoritative by design.
Before We Go Further, One Critical Distinction on why Claude, Grok, ChatGPT in a Browser Is Harmless — and Agents Are Not
When you type into Claude / Grok / GPT in a browser, you are using a sandboxed interface.
That system can:
generate text
hallucinate
drift
freeze
confuse itself
But it cannot:
touch your filesystem
execute code
move money
deploy infrastructure
change permissions
call tools unless you explicitly do it
The browser is the execution gate.
Worst-case failure:
You close the tab.
That’s why hallucinations there are annoying, not dangerous.
Now compare that to “no-code agents” and API-driven automation
When you:
wire ClaudeCode / GPT / Grok to APIs
give it tool access
let it write files, call services, deploy code, send emails, move data, access contact or client lists
allow “autonomous” loops
You have done something fundamentally different:
👉 You have embedded a probabilistic model inside a system that can act.
At that moment:
hallucination ≠ wrong answer
drift ≠ confusion
confidence ≠ style
They become:
incorrect execution
unauthorized action
irreversible side effects
Of an intelligent system acting inside your security perimeter.
Same model.
Different architecture.
Radically different risk.
The critical mistake these builders are making
They think:
“The model worked fine in Claude Chat, so it’ll be fine in production.”
That’s like saying:
“This car idles fine in neutral, so brakes are optional at highway speed.”
No.
The model was never the safety mechanism.
The system around it was.
The real failure mode (say this slowly)
LLMs:
hallucinate
are confidence-weighted, not truth-weighted
do not know when they are wrong
do not track authority
do not understand irreversibility
So if your architecture allows:
model output → tool call → execution
without admissibility, identity, authority, and rollback gates
You didn’t build an AI system.
You built:
a permission amplifier for uncertainty
That’s why hosted models are safe to give you: they cannot act without an application granting them permission.
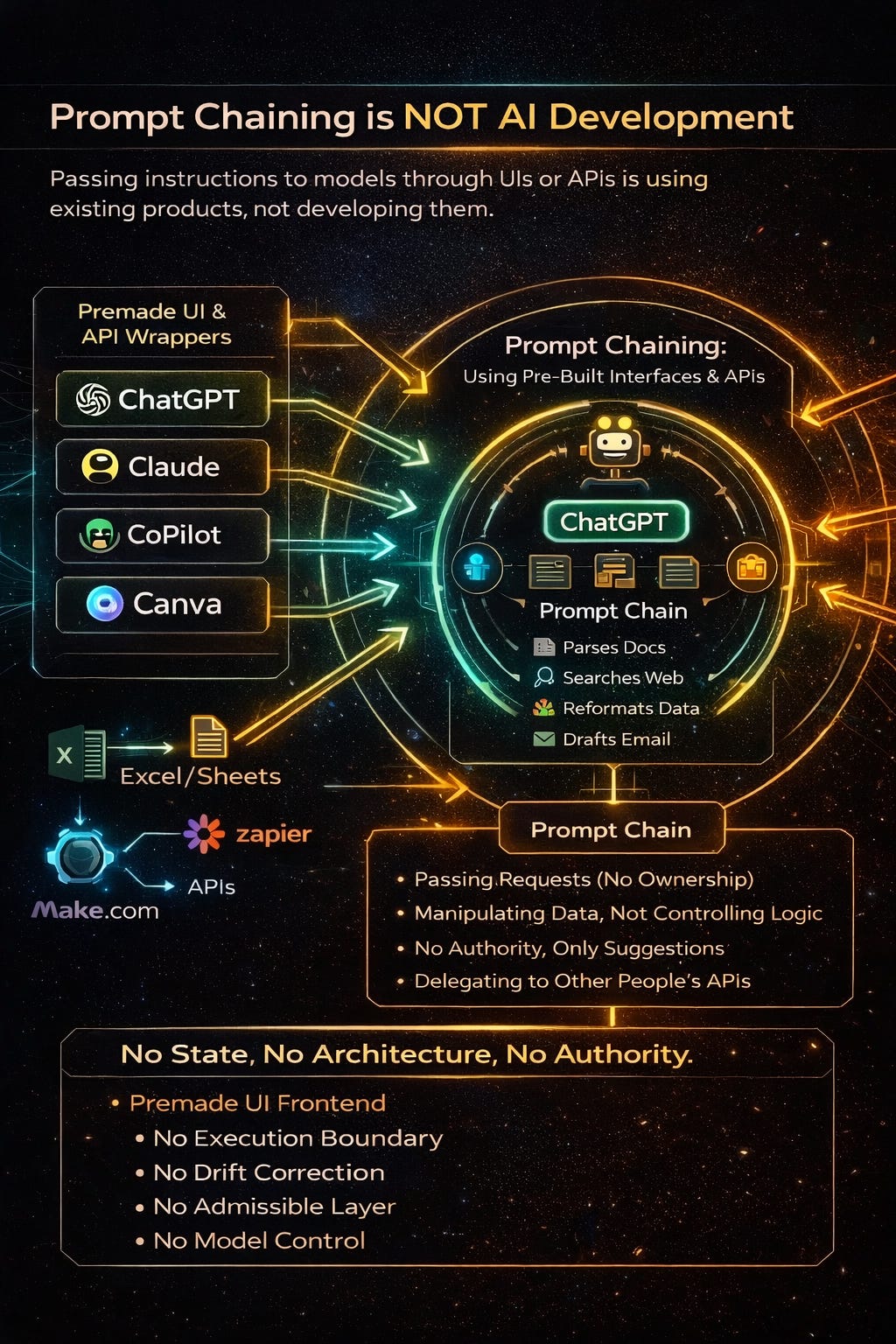
The Line You Cross When You’re Actually Developing AI
You are developing AI only when you build the system that decides what is allowed to happen.
That’s the execution boundary.
Everything before that is suggestion. Everything after that is liability.
Here’s what that path actually looks like.
The Real Development Path (No Vibes, Just Work)
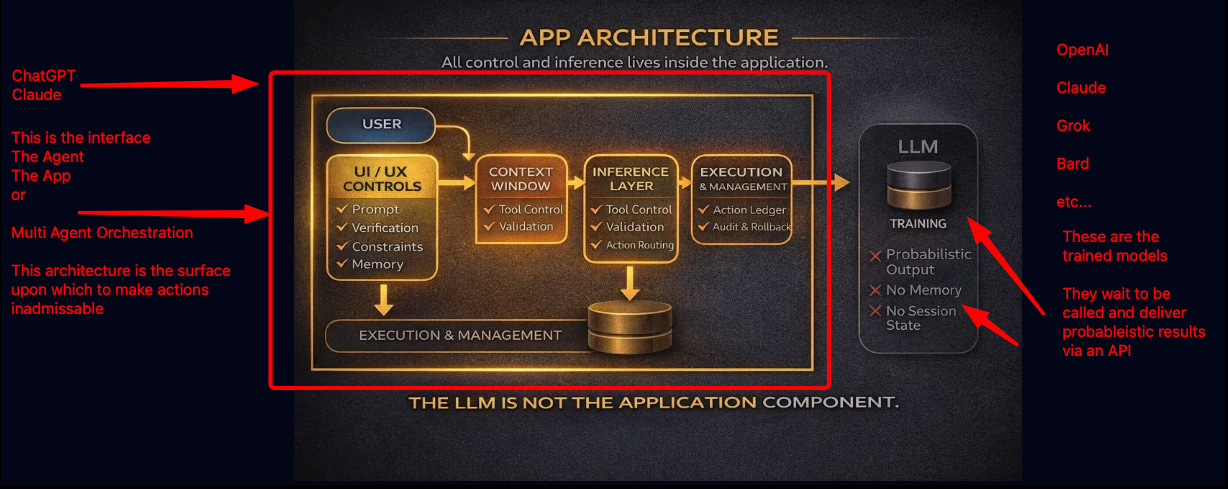
1. You Build an Application (Not a Prompt)
You install real tooling:
React, Vue, or another frontend
A backend (Python, Node, Go, etc.)
Docker or equivalent runtime isolation
CI/CD
Secrets management
This is where most “AI builders” quietly stop.
But this is just scaffolding.
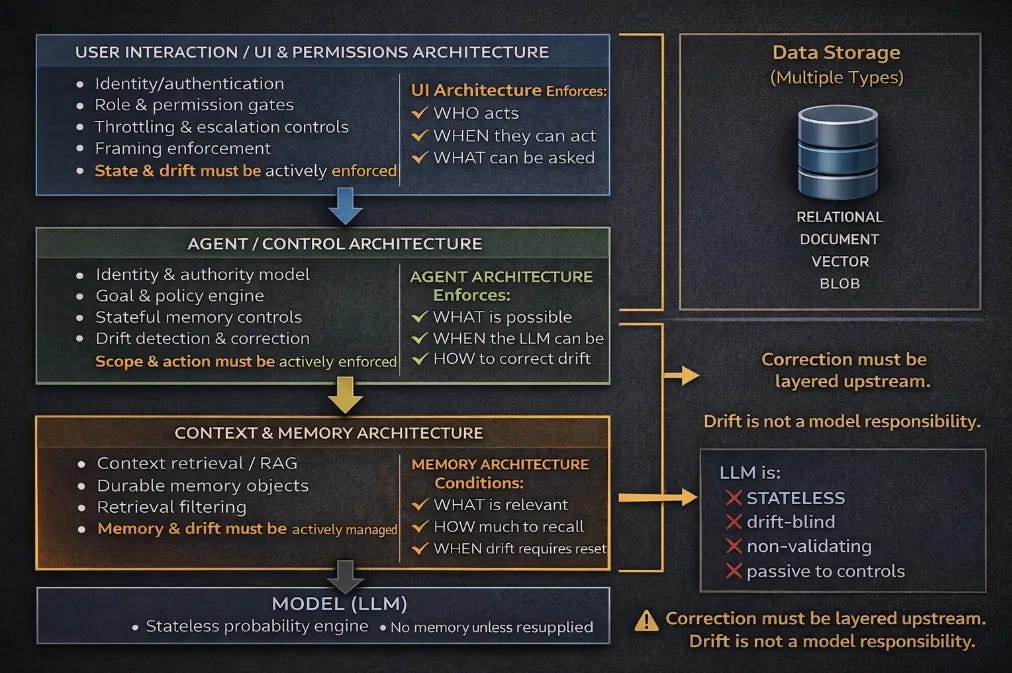
2. You Own State
LLMs are stateless. Systems are not.
So you build:
Databases (Postgres, Mongo, vector stores)
File storage
Session memory
User identity
Persistence across time
If your system forgets everything on refresh, it’s not intelligent — it’s disposable.
3. You Expose Capabilities the Model Does Not Have
Models cannot:
Browse the web
Read local files
Access private data
Take actions
You must build:
APIs
File ingestion pipelines
Parsers
Indexers
Retrieval layers
The model doesn’t “know” anything.
It is fed.
4. You Define the Execution Boundary (This Is the Moment)
This is where AI development actually begins.
You must explicitly decide:
What actions are allowed
What actions are inadmissible
When the system must refuse
When it must escalate to a human
When it must halt entirely
This is admissibility.
No admissibility layer = no system.
Without it, you are just streaming text.
5. You Implement Drift Correction
Real systems change over time.
So you build:
Constraint enforcement
Validation checks
Refusal logic
Rollbacks
External verification
Audit trails
This is where reliability lives.
Not in “alignment”.
Not in “ethics statements”.
In architecture.
6. Only Now Does the Model Matter
At this point, the model becomes interchangeable.
You can swap:
OpenAI
Claude
Local models
Fine-tuned variants
Because the model is no longer the authority.
Your system is.
The Acid Test (No One Likes This Question)
Ask yourself:
If the model produces a dangerous or incorrect output, can it cause harm without my system allowing it?
Here you should be able to immediately say no way. A reply coming from the model to my agent or app cannot produce harm I have accounted for that in my architecture and drift remediaction.
If the answer is yes — you didn’t build AI.
You delegated authority without constraint.
If the answer is no — now you’re doing real work.
Why This Distinction Matters (Legally and Practically)
Liability does not attach to suggestions.
It attaches to permission.
The moment your system:
Denies a benefit
Triggers enforcement
Executes an irreversible action
…the responsibility lives in your architecture, not in the model.
That’s why “prompt engineers” don’t get sued.
System builders do.
The Bottom Line
Using ChatGPT is not AI development.
Prompt chaining is not architecture.
Interfaces do not confer authority.
AI is developed when you build the system that decides what is allowed to happen.
Everything else is just talking to a machine.
And that’s fine — just don’t confuse it with engineering.
If you want to go deeper on this distinction and see the architecture laid out end-to-end, start here:
This isn’t about gatekeeping.
It’s about finally calling things by their real names.
Remembering, liability does not attach to suggestions. It attaches to permission.
When Systems Wobble, It’s Rarely Random
AI hallucinations. Governance failures. Strategy drift.
Different symptoms — same architectural failure.
Over the past year, I’ve mapped a repeatable failure pattern across AI systems, institutions, markets, and organizations, formalized as the Drift Stack.
The diagnostic identifies which layer is failing — and why coherence is being lost.
If you are deploying AI systems that can take action — deny, trigger, flag, enforce, decide — this call determines whether that authority is safe to delegate.
Drift Architecture Diagnostic — $250
A focused 30-minute architectural review to determine whether the issue sits in:
Identity
Frame
Boundary
Drift
External Correction
If there’s a deeper structural issue, it becomes visible quickly.
If not, you leave with clarity.
👉 Drift Assessment Info: https://www.samirac.com/drift-assessment
👉 Full work index: https://www.samirac.com/start-reading
—
Chris Ciappa
Founder & Chief Architect, Samirac Partners LLC
Drift Stack™ · SAQ™ · dAIsy™ · Mind-Mesch™